

%25201%2520(1).jpeg)
A scientific reasoning model for chemistry
Our mission is to automate scientific discovery. In the last few months, we have released agents that do much of the work of scientists – literature search, hypothesis generation, and data analysis. However, agents are limited by the intelligence of the underlying models, and the tools they have access to. For problems that require specialized scientific intelligence, we will need specialized models that have been trained on the problems in question.
Reasoning models have become the frontier of language model intelligence, breaking through benchmarks — especially in math and programming. Today, we are releasing a 24B open-weights reasoning model, ether0, that has been trained on tasks in chemistry. It is particularly good at designing drug-like molecules. It takes questions in natural language, reasons in natural language, and answers with molecules. Ether0 is still a prototype, but we have derived several important insights from our ether0 study that show us a path towards general purpose scientific reasoning models in the future. ether0 is now available as a tool for scientific agents on our platform and is available for download on Hugging Face.
Reinforcement Learning from the Physical World:
ether0 is a reasoning model trained with reinforcement learning. A reasoning model starts an answer with a series of specially marked “reasoning tokens” before completing with a final answer. These extra reasoning tokens are still in natural language, but can drift between languages and even mix in words made-up during training. These tokens are not trained to imitate a reference like standard language models; they emerge through reinforcement learning based only on the correctness of the final answer.
LLMs today know a lot about chemistry. The best models are OpenAI’s o3 and Opus 4, which score better than human experts in chemistry benchmarks like ChemBench or GPQA. They can chat about electron withdrawing groups or how to workup an amide coupling. Nonetheless, they are bad at actually working with molecules. They struggle to count the number of oxygens in a molecule, propose implausible ring structures, and are not good at naming molecules. We reasoned that, because modern LLMs have so much latent knowledge stored in their weights about how chemistry works, a small amount of reinforcement learning might be able to rapidly boost their performance on tasks that involve working with molecules.
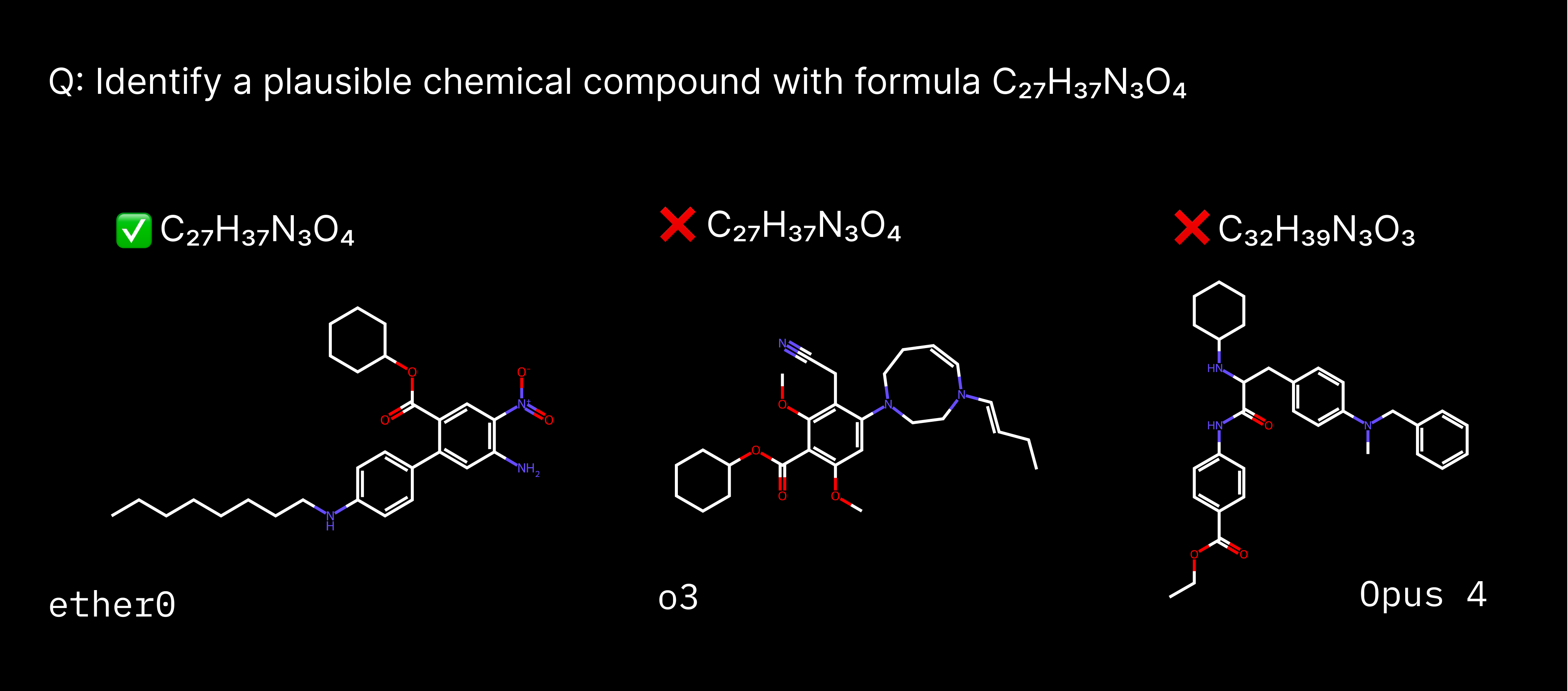
To test this hypothesis, we started from the Mistral 24B Instruct model released in early 2025 and trained it in successive rounds of reinforcement and fine-tuning, where we combined worked-out chains of thought with correct answers to distill knowledge from one model to another. The fungibility of chains of thought enables specialization at various stages of the process - making it simple to distribute training. Indeed, we found that not only are small open source models like Mistral 24B able to exceed the performance of frontier models on molecular design tasks in chemistry; in some cases, they also learn those tasks much more efficiently than specialized models trained from scratch on the same data.
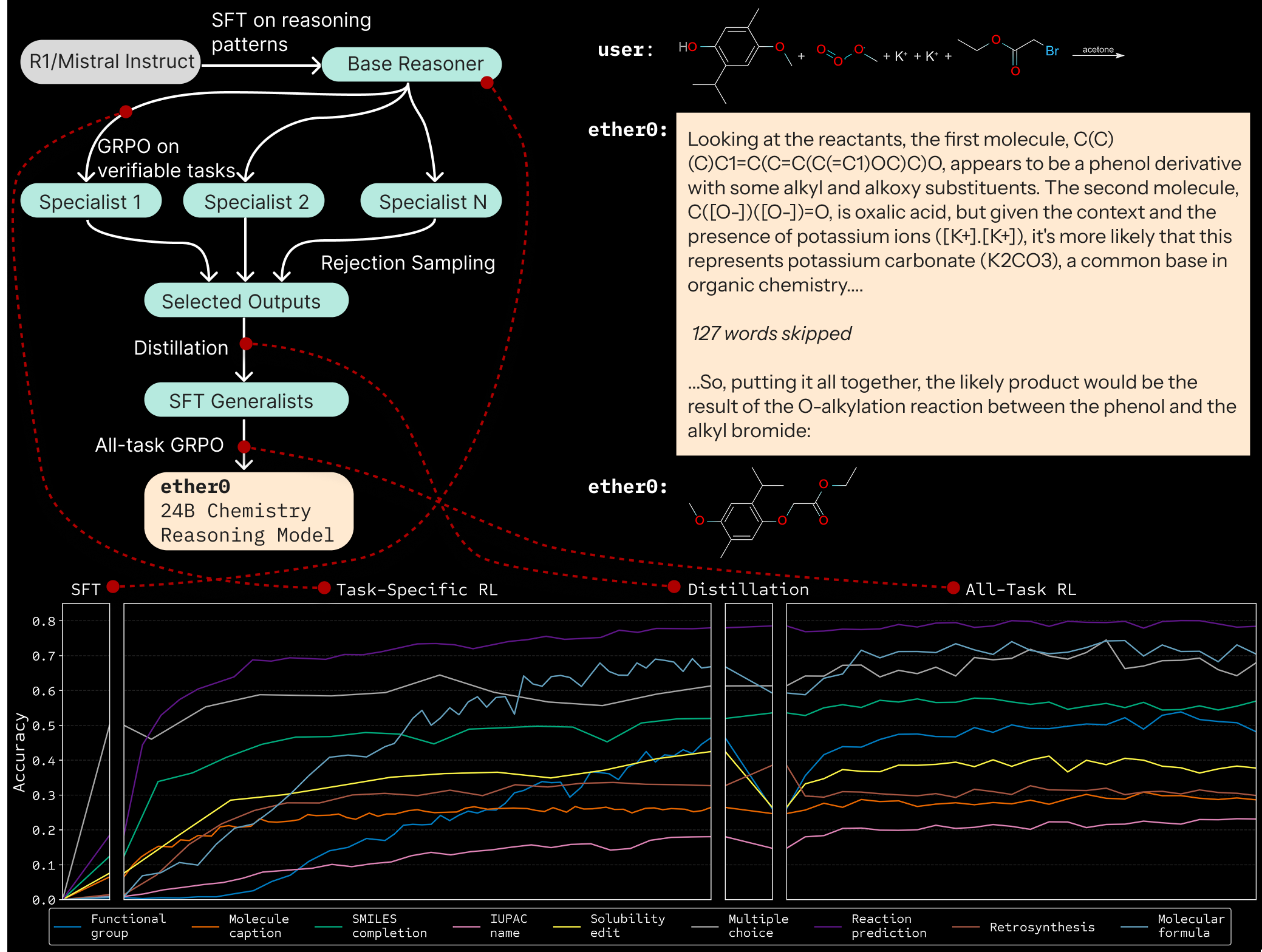
ether0 is exciting beyond chemistry because it has a much smaller parameter count than frontier models and is trained with about 50k examples per task. This is a manageable hurdle across scientific domains.
It has been debated in previous papers about what, if any, capabilities can be taught to a language model during the post-training reinforcement learning phase (e.g., see A, B, C). In this work, we have completely novel tasks (such as the “functional group” task) that are not in pretraining. The model is able to learn them. One of our tasks had no examples to start SFT with and was steady at 0% accuracy until 100 training steps in. Then it randomly got some correct, and started gaining. This is an exciting data point in the ongoing debate of when and how language models acquire reasoning capabilities.
What is ether0 like?
ether0 is fundamentally a research model. It’s exciting and represents a real advancement over existing models for designing molecules, but it’s not perfect. It struggles at recalling knowledge-based questions like common names for compounds, or obscure reaction classes. We didn’t consider conformations or shapes of molecules. It doesn’t do well on standardized tests in chemistry like ChemBench. It doesn’t hold a conversation. But it is really really good at designing molecules.
.png)
One of the most fun things about this project is seeing how a model morphs from a language model into a competent reasoning model. It starts to mix in more languages. It actually invents new words, and then they become part of its vocabulary in subsequent training steps. It makes “mental” shortcuts in its reasoning - omitting parts of molecules or just drifting off into a tangent and babbling. Some chemists find the reasoning helpful or interesting, and some find it too alien to be useful. We found that the longer we train for, the more alien the reasoning becomes.
If you want to try chatting directly with the model, you can do so at this small streamlit app we set up. Do remember to ensure the answer to your question will be a molecule.
Safety
We take dual-use risk seriously at FutureHouse and already monitor and filter our deployed scientific agents on our platform. Since this is an open-weights model, we also did post-training safety mitigation to prevent misuse of the model. We primarily considered internationally controlled compounds. Generally, the model will refuse to design such molecules. The model has little to no utility on “tacit” knowledge such as setting up reaction conditions, workups, etc. We red-teamed the open-weights model as reported in our manuscript for general risk.
Community
This work is the result of a huge team effort, great partners, and a strong open-source community. We built off the 24B Mistral Instruct model, which has worked well for us in chemistry. VoltagePark has been our GPU provider for the majority of this work, enabling us to rapidly test many ideas and train at the scale of hundreds of GPUs. NVIDIA has worked with FutureHouse on multiple projects, including this one, providing technical advice and support for training on their GPUs. Though we wrote our own RL code to experiment more flexibly, we started our early experiments with Huggingface's TRL and OpenR1 repositories.
We are contributing back to the open source community too. We are releasing the model weights, the preprint describing our training process (including data composition), and the reward model and benchmark for comparing future models. The reward model and various helpful utilities for working with molecular design are available here: github.com/Future-House/ether0. The benchmark and weights are on HuggingFace (see links below). We’re looking forward to seeing where our model can be useful and seeing what new models can be created!
What’s next
This is an early step towards building an AI scientist that can make connections humans do not. We are putting this model today into our chemistry agent (Phoenix) for designing molecules and the weights are released under a permissive open Apache 2.0 license. We hope this is both a great model for chemistry and a path that can be followed across many more domains of science. If you want to be part of our mission of accelerating scientific discovery, consider applying at FutureHouse!
Info
You can
- Preprint: arxiv.org/abs/2506.17238
- Model: huggingface.co/futurehouse/ether0
- Reward code: https://github.com/future-House/ether0
- New Benchmark: huggingface.co/datasets/futurehouse/ether0-benchmark
- Try it out: ether0.platform.futurehouse.org

