

As scientists, we stand on the shoulders of giants. Scientific progress requires curation and synthesis of prior knowledge and experimental results. However, the scientific literature is so expansive that synthesis, the comprehensive combination of ideas and results, is a bottleneck. The ability of large language models to comprehend and summarize natural language will transform science by automating the synthesis of scientific knowledge at scale. Yet current LLMs are limited by hallucinations, lack access to the most up-to-date information, and do not provide reliable references for statements.
Here, we present WikiCrow, an automated system that can synthesize cited Wikipedia-style summaries for technical topics from the scientific literature. WikiCrow is built on top of FutureHouse’s internal LLM agent platform, PaperQA, which in our testing, achieves state-of-the-art (SOTA) performance on a retrieval-focused version of PubMedQA and other benchmarks, including a new retrieval-first benchmark, LitQA, developed internally to evaluate systems retrieving full-text PDFs across the entire scientific literature.
As a demonstration of the potential for AI to impact scientific practice, we use WikiCrow to generate draft articles for the 15,616 human protein-coding genes that currently lack Wikipedia articles, or that have article stubs. WikiCrow creates articles in 8 minutes, is much more consistent than human editors at citing its sources, and makes incorrect inferences or statements about 9% of the time, a number that we expect to improve as we mature our systems. WikiCrow will be a foundational tool for the AI Scientists we plan to build in the coming years, and will help us to democratize access to scientific research.
Background
If you’ve spent time in molecular biology, you have probably encountered the “alphabet soup” problem of genomics. Experiments in genomics uncover lists of genes implicated in a biological process, like MGAT5B and ADGRA3. Researchers turn to tools like Google, Uniprot or Wikipedia to learn more, as the knowledge of 20,000 human genes is too broad for any single human to understand. However, according to our count, only 3,639 of the 19,255 human protein-coding genes recognized by the HGNC have high-quality (non-stub) summaries on Wikipedia; the other 15,616 lack pages or are incomplete stubs. Often, plenty is known about the gene, but no one has taken the time to write up a summary. This is part of a much broader problem today: scientific knowledge is hard to access, and often locked up in impenetrable technical reports. To find out about genes like MGAT5B and ADGRA3, you’d end up sinking hours into reading the primary literature.
WikiCrow is a first step towards automated synthesis of human scientific knowledge. As a first demo, we used WikiCrow to generate drafts of Wikipedia-style articles for all 15,616 of the Human protein-coding genes that currently lack articles or have stubs, using information from full-text articles that we have access to through our academic affiliations. We estimate that this task would have taken an expert human ~60,000 hours total (6.8 working years). By contrast, WikiCrow wrote all 15,616 articles in a few days (about 8 minutes per article, with 50 instances running in parallel), drawing on 14,819,358 pages from 871,000 scientific papers that it identified as relevant in the literature.
Our articles are still far from perfect. To evaluate WikiCrow, we randomly selected 100 statements and asked:
- Is the statement cited? Is there a nearby citation that is clearly intended to support this statement, and is the citation relevant?
- Is the statement correct according to the citation? Does the cited literature contain the information that is presented in the statement being evaluated?
All statements were thus characterized as either having irrelevant or missing citations; being cited and correct; or being cited and incorrect. We then repeated the same process for human-written articles. The results are as follows:

As you read WikiCrow articles, you will see incorrect statements about 9% of the time. You may also see repetitive statements, or citations that aren’t correct. We expect that these errors will become rarer as the underlying models and techniques improve. On the other hand, WikiCrow is much better at providing citations than human authors. Make sure to check any information you read here yourself before relying on it, and please alert us to any errors you may find. For more technical details, read on:
PaperQA as a Platform for WikiCrow
WikiCrow is built on top of PaperQA, a Retrieval-Augmented Generative (RAG) agent that, in our testing, can answer questions over the scientific literature better than other LLMs and commercial products. (See our paper on PaperQA) PaperQA reduces hallucinations, provides context and references for how an answer was generated, is orders of magnitude faster than humans, and retains accuracy on par with experts.
PaperQA is more than just a search tool; it is an adaptive system that uses tools based on the question and intermediate research. These tools include:
- SEARCH: finding relevant papers from online databases, such as Arxiv and Pubmed;
- GATHER_EVIDENCE: parsing and summarizing text from these papers;
- ANSWER_QUESTION: ranking the relevance of the gathered context and synthesizing information into a final answer.
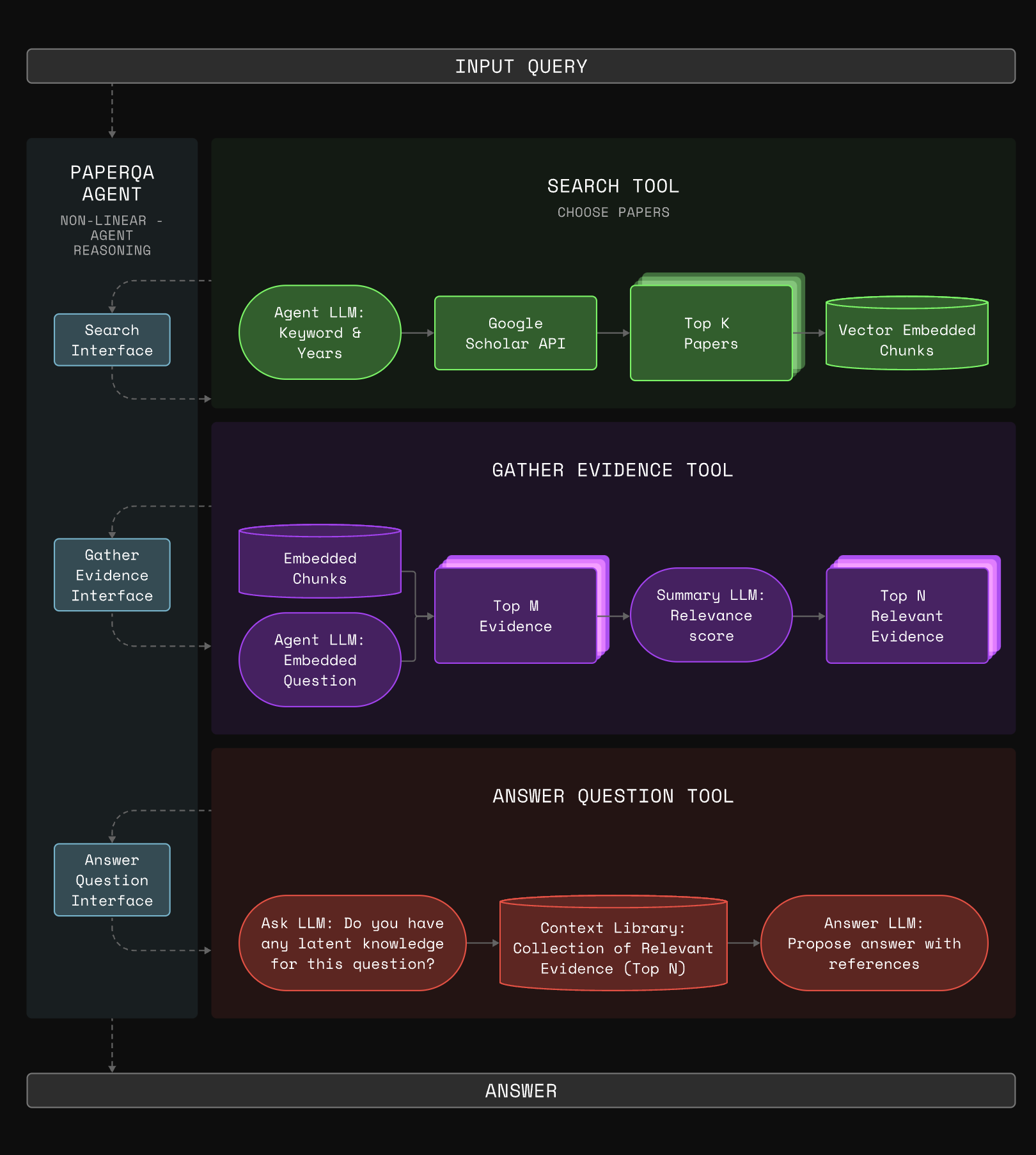
This process is non-linear. For example, if PaperQA sees a paper that uses a different word to refer to a concept, it can go back and search again with the new nomenclature. Compared to a standard RAG, PaperQA makes four key changes (each improved performance, measured via ablation testing):
- PaperQA breaks down the Retrieve and Generate (RAG) process into tools for an AI agent, enabling it to perform multiple searches with various keywords whenever the information at hand isn't enough.
- PaperQA employs a Map-Reduce inspired approach to summarization, where the AI first collects (maps) evidence from a range of sources and then condenses (reduces) this information to provide an answer. This increases the amount of sources that can be considered, enabling the LLM to provide preliminary insights before composing the final answer.
- PaperQA uses a hybrid search approach to work on all accessible papers, which number in the 100s of million. Namely, PaperQA uses LLM-assisted keyword search at the corpus level and semantic search at the granular level of pages of text.
- PaperQA implements prior-knowledge prompting strategies to access and utilize the underlying knowledge embedded within language models, when needed finding evidence in the scientific literature, and uses the resulting answer as a type of posterior knowledge.
Importantly, PaperQA builds upon the unique structure of scientific literature – its citation graph and categorization into journals and fields. This is only possible due to the excellent contributions of the Semantic Scholar team at Allen Institute for AI, whose API for exploring the citation graph of science is a key feature of PaperQA. We plan to make the full WikiCrow and PaperQA code available on GitHub soon. Until then, the essential aspects of the PaperQA algorithm are available (although you will need access to your own repository of full text scientific articles), as well as the prompts used for WikiCrow.
Benchmarking PaperQA
In our evaluations, PaperQA outperforms GPT-4, Perplexity, and other LLMs, as well as commercial RAG systems on several benchmarks. We show excellent performance on two scientific question-answering benchmarks - MedQA-USMLE and PubMedQA Blind, the latter of which is a modified version of PubMedQA, where original contexts are removed to challenge the system to find the papers to retrieve the context. Additionally, PaperQA outperforms a range of systems on LitQA, a new benchmark that we developed to validate our performance. LitQA consists of multiple-choice questions that are difficult or impossible to answer accurately without retrieval of one or more specific papers, all of which were published after the training cutoff dates of GPT-4 and Claude 2 in 2022. Today, LitQA is small, with only 50 questions, as it is extraordinarily time-consuming to generate and validate these types of questions, but we plan to scale it up in the future. Also note that we performed this testing in October 2023 (outside of Gemini Pro in December 2023) and did not try to optimize any of the commercial systems here, so it’s possible they could be engineered for higher performance, or would have higher performance if tested today.

